【本报记者 司平】3月17日,日本互联网巨头乐天发布了最新人工智能大模型Rakuten AI3.0,却把自己卷入了一场舆论风暴。乐天官方和部分新闻稿件高调地将之称为“日本最强”模型;然而其在美国的开源社区上线不久,就被眼尖的技术人员在底层架构的代码中发现了“deepseek_v3”的字样。
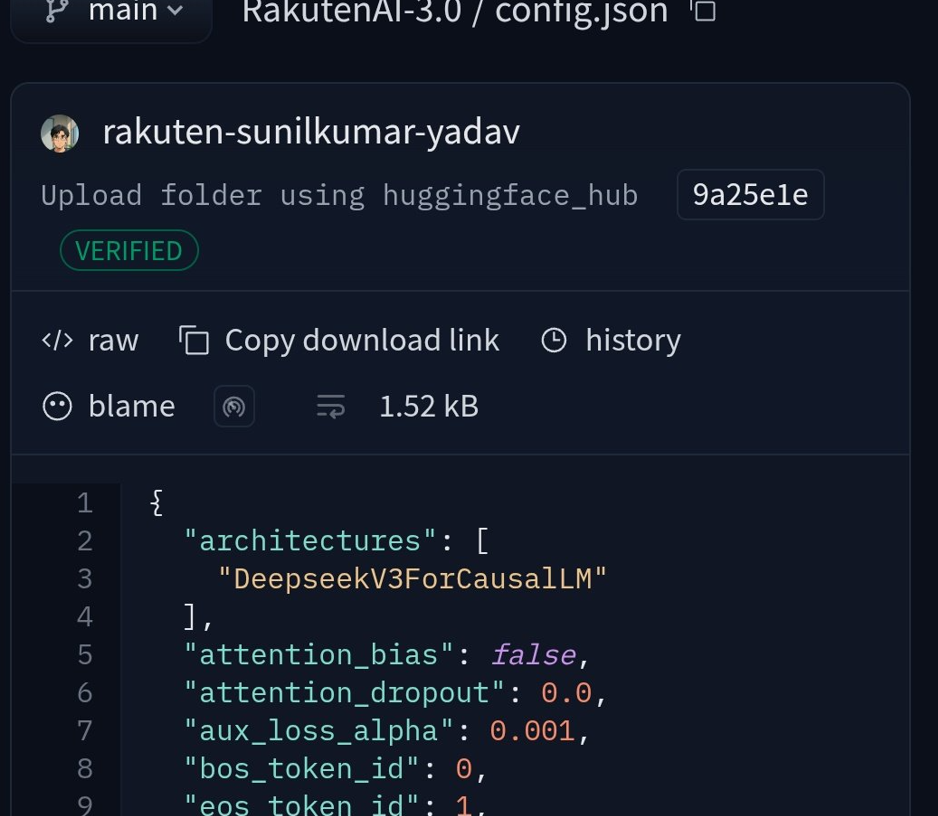
一瞬间,“日本最强”沦为“中国套壳”。这样的故事在近期似乎太多,在两国的社交平台上激起了人们意料之中的反响,有人“义愤填膺”,有人“幸灾乐祸”。然而当我们跳出情绪,回归技术常识,倒也不妨问一句:乐天套壳DeepSeek,有何不可?
乐天模型出了什么问题
与DeepSeek-V3同样,Rakuten AI3.0也是一个7000亿级参数的大体量模型,采用V3的混合专家架构。根据乐天官方发布的测试,该模型在处理日本特定的文化知识、研究生级逻辑推理、竞技性数学等方面表现优异,部分指标超越了目前业界的公认标杆GPT-4o。
从报告可以看出,乐天团队的主要工作,在于利用自身庞大的商业生态积累下来的高质量日语语料,对DeepSeek进行本土化改造,使之适应日本的文化环境。在当下的生成AI产业分工中,基础大模型训练和垂直领域微调是两条不同的赛道。使用全球顶尖的开源权重进行二次开发,是绝大多数非头部AI企业的标准商业动作,既不违规,也不存在欺骗。
不过,乐天的尴尬另有原因。外界注意到,产品宣发过程中,无论是初期准备阶段,落地宣传还是主流媒体的商业稿件,都只模糊地承认该产品“基于开源社区最优秀的模型”,但绝口不提DeepSeek的存在。这导致日本网友在发现情况时,也出现了相当大的心理落差。
在不够诚恳的公关策略背后,是这款模型被赋予的过高的战略定位。Rakuten AI3.0在去年夏天拿到了日本经济产业省的国家补贴,也是日本纳税人的心血,承载着日本社会对所谓“主权AI”“纯国产AI”的民族情绪。皮一剥开,它的底层核心是一家中国的科技公司,这无疑触动了某些敏感的神经。乐天原本可以坦荡地展示其技术整合能力,如此遮遮掩掩的处理方式,反而招致了怀疑和批评。
为什么是DeepSeek?
在日本当地一些AI从业者看来,乐天选择DeepSeek-V3作为框架,不仅是可接受的,也是“最优解”。首当其冲的原因当然是开源协议的合法性。DeepSeek是一款开源模型,乐天以Apache2.0等许可证发布其微调后的模型,完全符合国际社区的规则。
这也是出于算力成本的现实考量。从零开始训练一个拥有数千亿参数的顶级模型,需要耗费天文数字的算力和资金。曾供职于IBM的业内人士川村正春指出,目前日本国内也几乎没有企业具备从零单干这种规模AI的计算资源池。DeepSeek-V3架构不仅性能顶尖,推理和训练成本也极低。在急速迭代的人工智能产业中,期待乐天拿着日本政府有限的算力补助“平地起高楼”,这是缺乏经济合理性的。相反,站在开源的肩膀上,将有限的资源用于数据注入和领域微调,是投入产出比最高的选择。
最后还有一个原本不值一驳的数据安全问题。部分日本网友担忧,使用中国模型会导致“数据外泄”,这一说法已得到不少日本业内人士的纠正。情况恰恰相反:依赖ChatGPT等闭源的API服务,才需要将数据跨境传输到其他国家和地区的服务器;而采用DeepSeek的开源模型,则意味着乐天可以将整个模型下载部署在自己控制的本地服务器内,是最“安全”的。
另一边,少部分中国评论在此事中再度给日本技术“判死刑”,这也没什么必要。AI大模型的竞争不只在底座的参数规模,也在于应用场景的落地。乐天利用本土数据将大模型调教为适应日本商业生态的工具,这种工程能力值得各国参考借鉴。况且,DeepSeek诞生之初,最受追捧的就是开源的技术浪漫主义:它承诺不搞垄断和租赁,鼓励共享和二次开发,这是值得我们骄傲的。
在这个意义上,Rakuten AI3.0是一次成功的“握手”。在生成式AI开发的长跑中,没有哪个团队能完全闭门造车,也没有必要将所谓原产地“武器化”。坦荡承认合作,自信展示二次开发的意义,这或许才是科技企业最应具备的风范,也是互联网用户应当拥护的价值。
